
Computations have no ethical subroutine. And understanding bias in AI is an important eye opener. Building an AI-facilitated future without properly understanding the algorithms behind the conclusions and actions is leading us to into unexpected pitfalls.
We are all very excited about machine learning and AIs. We see them as the ultimate way of automating daily life from driverless cars to personal health and medical diagnostics. But garbage in = garbage out. And to eliminate the garbage we need to be able to identify it. Long after our little helper has started working.
The main reason we need to watch out is that AI algorithms are not necessarily retraceable and retrackable. Not even the programmer understands it fully once the machine starts accumulating and filtering data. Despite its ability to learn it can only conclude based on the original assumptions built into the underlying algorithms.
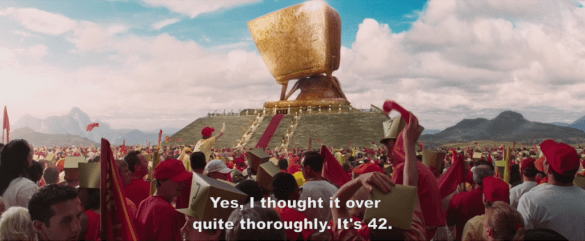
Looking for the ultimate answer
Whenever we rely on algorithms to make decisions – or at least recommendations – it is because we seek a simple answer to a complex question.
If the collection of big data for data driven decision making is used to create simple answers to complex questions, the complexity is solved through algorithms that in effect filter and collate based on what the human programmer considered applicable. And it concerns us more than you would expect. I recently read that the AI concept is being used within the US judicial system: Judges rely on the AI’s suggestion on whether an inmate should be granted parole based on assumptions of future behavior of set individual after release. In isolation this would seem like a statistically viable method, as there will be vast amount of available data to substantiate the conclusion.
But if the original algorithms input by a human were in fact influenced by bias such as race, name, gender, age etc., are the conclusions any better than the answer 42?
When Douglas Adams in his science-fiction Hitchiker’s Guide to the Galaxy series introduced Deep Thought, the biggest computer ever built in the history of men and mice, the builders asked for the answer – and added that they wanted it to be nice and simple. So after millions of years Deep Thought concluded that the answer to life the universe and everything was 42. But by now, this insight was useless because nobody really understood the question.
If we see AI and machine learning as the ultimate answer to complex scenarios, then we must be able to go back to the original question in order to be able to process the answer. Not just to understand but to analyse and apply what the computer is missing – the ethical subroutine.
What will the AI choose in a no-win scenario?
One of the hot topics in the current discussion around self driving cars is whether the AI would make proper ethical decisions in a no-win scenario. Should it risk the life of the passenger by veering off the street and over a cliff to avoid running over another individual in in the street? The decision would be entirely based on the original algorithms which overtime have become inscrutable even for the engineers themselves.
Of course, this is a simplified example. An AI, as opposed to a human behind the wheel, would be able to process more details regarding the potential outcome of either option. What would the statistical probability of successfully avoiding hitting the person on the street be when taking into account elements such as speed, space available without going over the cliff, the chance of the person acknowledging the danger and moving out-of-the-way in time before the collision etc.

(Image from Nvidia Marketing Material)
But the self preservation instinct of a human being behind the wheel would most likely lead to the obvious conclusion: Hitting the person is preferable to dying by plunging over the cliff! Would the original programmer not have input exactly this type of bias?
What I believe Douglas Adams was getting at with the magic number 42 was that there is no simple answer to complex questions. If as indicated above the AI is victim to its own programming when making complex decisions or recommendations, then as a tool we must make it as transparent and thereby manageable as any tool developed by humans since the invention of the wheel.
MIT Technology Review addressed this in detail in the article published by Will Knight in April 2017 The Dark Secret at the Heart of AI
“No one really knows how the most advanced algorithms do what they do. That could be a problem.”
 He goes on to explain that while mathematical models are being used to make life changing decisions such as who gets parole, who gets a loan in the bank, or who gets hired for a job, it remains possible to understand the reasoning. But when it comes to what Knight calls Deep Learning or machine learning, the complexity increases and the continuosly evolving program eventually becomes impossible to backtrack even for the engineer who built it.
He goes on to explain that while mathematical models are being used to make life changing decisions such as who gets parole, who gets a loan in the bank, or who gets hired for a job, it remains possible to understand the reasoning. But when it comes to what Knight calls Deep Learning or machine learning, the complexity increases and the continuosly evolving program eventually becomes impossible to backtrack even for the engineer who built it.
Despite the inscrutable nature of the mechanisms that lead to the decisions made by the AI, we are all too happy to plunge in with our eyes closed.
Later the same year another MIT Technology Review article explores the results of a study of the algorithms behind COMPAS (Inspecting Algorithms for Bias ) COMPAS is a risk assessment software which is being used to forecast which criminals are most likely to reoffend.
Without going into detail – I highly recommend you read the article – the conclusion was that there was a clear bias towards blacks. The conclusions later turned out to be incorrect assumptions: Blacks were expected to more frequently reoffend, but in reality did not. And vice versa for the white released prisoners.
The author of the article, German journalist Matthias Spielkamp, is one of the founders of the non-profit AlgorithmWatch which has taken up the mission to watch and explain the effects of algorithmic decision making processes on human behaviour and to point out ethical conflicts.

Mattias Spielkamp, Founder of AlgorithmWatch
The proverbial top of the iceberg
Even strong advocates of applying artifical intelligence/cognitive intelligence and machine-learning (deep learning) to everyday life applications, such as IBM with its Watson project, are aware of this threat and use strong words such as mitigation to explain how this potential outcome of widespread use of the technology can be handled better.
In a very recent article published February 2018 entitled Mitigating Bias in AI models , Ruchir Purri, Chief Architect and IBM Fellow, IBM Watson and Cloud Platform stresses that “AI systems are only as effective as the data they are trained on. Bad training data can lead to higher error rates and biased decision making, even when the underlying model is sound… Continually striving to identify and mitigate bias is absolutely essential to building trust and ensuring that these transformative technologies will have a net positive impact on society.”
IBM is undertaking a long range of measures to minimize bias but this is only addressing the top of the iceberg. The real challenge is that we are increasingly dehumanizing complex decisions by relying on algorithms that are too clever for their own good.
Actually – all of this isn’t exactly news.
More than 20 years ago, human bias was already identifed as an important aspect of computer programming
“As early as 1996, Batya Friedman and Helen Nissenbaum developed a typology of bias in computer systems that described the various ways human bias can be built into machine processes: “Bias can enter a [computer] system either through the explicit and conscious efforts of individuals or institutions, or implicitly and unconsciously, even in spite of the best of intentions”. (Source: Ethics and Algorithmic Processes for decision making and decision support )

Pingback: AI is good – or is it? – Making Sense of Technology